「SEO対策をしているのに、なぜか検索に出てこない」といった原因は、クローラーにあるかもしれません。
Googleをはじめとする検索エンジンは、サイトを自動で巡回・収集する「クローラー」を通じて情報を取得しています。このクローラーに正しく巡回されなければ、どれだけ優れたコンテンツを用意してもインデックスされず、検索結果に表示されることはありません。
この記事では、SEOにおけるクローラーの役割や仕組みを解説し、サイトが正しく巡回・評価されるための具体的な対策を解説します。検索上位を目指すための第一歩として、クローラビリティの理解と改善は欠かせない要素です。
目次
クローラーとは?SEOへの基本理解

検索エンジンにコンテンツを認識してもらうには、「クローラーによる巡回」と「インデックス登録」の2段階を経る必要があります。ここでは、その前提となるクローラーの役割を正確に押さえましょう。
クローラーの定義と種類
クローラーとは、Web上の情報を収集する検索エンジンの自動プログラムのことです。
代表的なものとして、Googleの「Googlebot」やBingの「Bingbot」などがあり、インターネット上のリンクをたどりながらページを巡回し、コンテンツ情報を取得します。
クローラーには複数の種類があり、PC用・スマートフォン用の他、画像や動画など特定のコンテンツに特化したものもあります。それぞれのクローラーが目的に応じた情報を集め、検索エンジンのデータベースに蓄積することで、検索結果の基盤が作られていきます。
検索エンジンとクロール・インデックスの関係
クローラーによってページが巡回されると、その内容はインデックス(検索データベース)に保存され、初めて検索結果に表示される対象となります。
巡回されなければインデックスもされず、検索流入は一切見込めません。つまり、いかにクローラーに正確に巡回してもらえるかが、SEOのスタートラインとなります。
また、クローラーの巡回には「クロールバジェット(巡回予算)」という概念があります。これは検索エンジンが1サイトに割り当てるクロールの上限のことで、サイトの規模や更新頻度によって変動します。
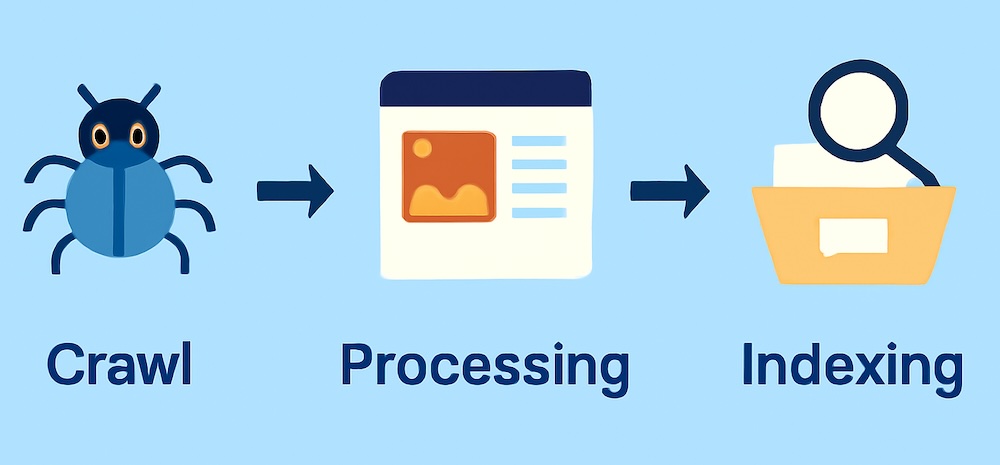
クローラーが巡回できない主な原因
いくら優れたコンテンツを用意しても、クローラーが巡回できなければインデックスもされず、SEO効果は得られません。ここでは、よくある巡回阻害の原因とその背景を理解しておきましょう。
robots.txtやnoindexの誤設定
クローラーの巡回を制御するために使われるのがrobots.txtやnoindexタグですが、これらの設定ミスによって、本来クロール・インデックスされるべきページがブロックされてしまうケースが少なくありません。
特に注意が必要なのが、WordPressなどのCMS(コンテンツ管理システム)を利用している場合です。初期設定のままや、開発中サイトの「公開忘れ」によって、意図せず全ページのクロールが制限されていることがあります。
また、HTML内に<meta name=”robots” content=”noindex”>タグを記載していたり、HTTPヘッダーでnoindexを指定していたりするる場合は、インデックスの除外を宣言していることになるため、該当ページが検索結果から除外されてしまいます。
内部リンクの構造不備・リンク切れ
サイト内のリンク構造が適切でないと、クローラーがページ間をうまく移動できず、特に階層の深いページが巡回されにくくなります。なかでも、トップページや他のページからリンクされていない「孤立ページ」は、クロールされにくい代表例です。
また、リンク切れ(404エラー)やリダイレクトループ(無限に転送が繰り返される状態)があると、クローラーはその先に進むことができず、巡回が中断されてしまいます。こうした不備は、サイト全体の評価にも悪影響を与えます。
JavaScriptや非対応形式の問題
JavaScriptで生成されるコンテンツや、Flashなどの非推奨技術で構築されたページは、クローラーが正しく情報を取得できない原因となります。たとえば、GooglebotはJavaScriptのレンダリングにも対応していますが、完全ではないため、重要情報はHTMLで直接出力するのがおすすめです。
また、動的に読み込まれるコンテンツや、スクロール動作に依存する「無限スクロール」なども、クローラーが巡回しきれない要因になります。
| 原因項目 | 内容の説明 | 推奨される対策 |
|---|---|---|
| robots.txtの誤記述 | 不要なページ全体をブロックしている | 必要なURLは許可、テストツールで確認 |
| noindexの残存 | 公開後もnoindexタグが残っている | タグを削除し、URL検査ツールで再送信 |
| 内部リンク不足 | 孤立ページや階層が深すぎる構造 | サイトマップ、パンくず、カテゴリ強化 |
| リンク切れ・リダイレクト不備 | 404・500エラーや無限ループなど | 定期的なリンクチェックツールで検出 |
| JavaScript依存の表示 | JSでしか見えないコンテンツや動的読み込み | HTMLに代替表示、SSR導入の検討など |
SEOに効果的なクローラー最適化施策

クローラーが効率的に巡回できるようにすることで、重要なページが確実にインデックスされ、SEOパフォーマンスの最大化につながります。ここでは実践的な4つの施策を紹介します。
サイトマップ送信とURL登録
XMLサイトマップをGoogleサーチコンソールに送信することで、クローラーに「優先的に巡回してほしいURL」を伝えることができます。
特に新規ページや階層の深いページがある場合は、サイトマップでの活用が効果的です。
あわせて、HTMLサイトマップも併用することで、ユーザーにとっての利便性を高めると同時に、クローラーにもサイト構造を伝えやすくなります。
このようにXMLとHTMLの両方を活用することで、巡回性とユーザビリティを両立させることが可能です。
内部リンク最適化・パンくず設置
サイト内の内部リンク構造を整理することは、クローラーが効率よく全ページを巡回できる導線をつくる上で非常に重要です。特に、重要なページはトップページから2〜3クリックで到達できるように設計し、階層構造をできるだけシンプルに保つことが理想です。
さらに、パンくずリストを導入することで、ページ間の関係性が明確になり、クローラーによる理解と巡回の精度が向上します。ユーザーにとっての利便性向上にもつながるため、SEOとUXの両面から有効な施策といえます。
クロールバジェットの管理と最適化
クロールバジェットとは、Googlebotが特定のWebサイトに対して1日に巡回する上限回数(クロール数)を意味します。この「巡回予算」は無限ではないため、不要なURLで無駄に消費しないよう管理することが重要です。
たとえば、パラメータ付きのURLや、同一内容が複数URLで存在するような類似ページは、noindexタグやcanonicalタグなどを用いて整理することが推奨されます。
また、404エラーやリダイレクトが多発すると、クロールバジェットが浪費されるため、定期的なクローラビリティチェックが欠かせません。
URL正規化とパラメータ管理
同じ内容のページに対して複数のURLが存在する場合、検索エンジンに「どのURLが正規のものか」を明確に示す必要があります。これをURLの正規化と呼びます。
正規化を徹底することで、検索評価が分散せず、インデックスやランキングの効率が向上します。
具体的には、canonicalタグや301リダイレクトを適切に使うことで、検索エンジンに正しいURLを伝えることができます。
また、URLパラメータがある場合は、サーチコンソールの「パラメータ設定」や、robots.txtでのアクセス制御を組み合わせることで、不要なクロールの発生を抑えることが可能です。
【概念図:最適化施策とクロール向上の関係】
サーチコンソールでクローラーの動きを確認する方法

クローラーの巡回状況を把握するには、Googleサーチコンソールのデータを活用するのが最も確実です。どのページがクロールされ、どこでエラーが起きているのかを可視化することで、改善の優先順位が明確になります。
「カバレッジレポート」「URL検査」の活用
Googleサーチコンソールの「インデックス作成」レポート内の「ページ」では、GoogleがクロールしたURLのステータス(有効・除外・エラーなど)を確認できます。特に「除外」や「エラー」に分類されているページは、インデックスされていないか、クロールに問題がある状態です。
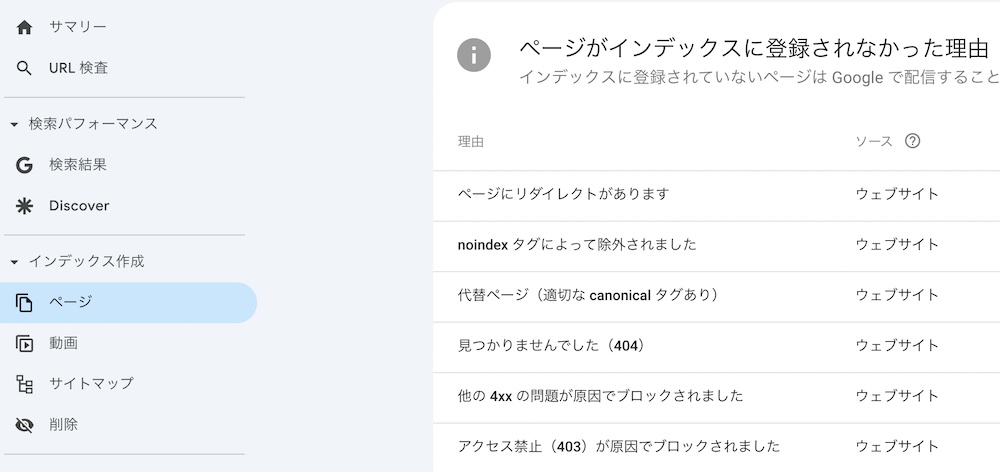
また、「URL検査」ツールを使えば、特定のページがクロール・インデックス済みかどうかを即座に確認できます。クロールできていない場合は、「インデックス登録をリクエスト」機能を使って、再クロールを促すことも可能です。
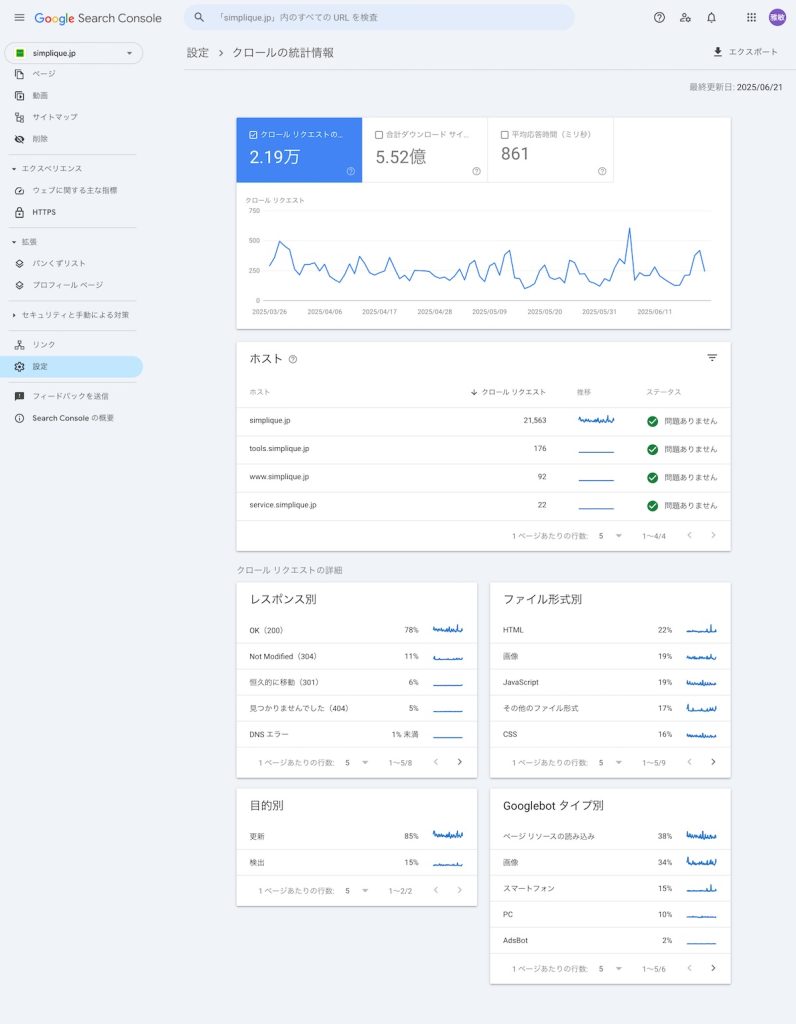
「クロールの統計情報」から巡回状況を把握
Googleサーチコンソールの「クロールの統計情報」(左メニュー「設定」内)では、Googlebotがどの程度の頻度で自社サイトを巡回しているかが数値で示されます。たとえば、1日あたりのクロールリクエスト数、ダウンロード時間、レスポンスコードの分布などから、クロールバジェットの傾向や巡回負荷の変化を分析できます。
特定の時期にクロール数が激減している場合は、robots.txtの設定ミスやサーバーエラーといった技術的な問題が発生している可能性もあるため、注意深く確認しましょう。
まとめ
SEOで成果を上げるためには、まずクローラーにサイトを正しく巡回・認識してもらうことがスタートラインです。どれほど質の高いコンテンツを用意しても、クローラーが巡回できなければインデックスされず、検索結果に表示されることもありません。
この記事では、クローラーの基本構造から巡回を妨げる原因、具体的な改善施策、そしてサーチコンソールを用いた確認方法までを解説しました。クローラビリティの最適化は、テクニカルSEOの土台となる重要な要素です。
定期的に確認と施策の見直しを行い、検索エンジンとの信頼性を高めていきましょう。
自社サイトのクロール状況を可視化し、SEO成果を底上げしたい場合は、テクニカルSEOの支援に強い「シンプリック」にご相談ください。貴社の課題にあわせた診断・改善提案で、検索パフォーマンスの最大化をサポートします。